The worst bugs I've shipped this year didn't come from code I wrote. They came from code Claude handed me with complete confidence, that looked right, read right, and was quietly wrong in a way I almost didn't catch.
This is the failure mode nobody names cleanly, so I'm going to name it: the AI bluff. The model produces something authoritative-looking — a function call, an API method, an explanation of a stack trace — and it's subtly off. Not gibberish. Not obviously hallucinated. Just wrong enough that it compiles, runs, and breaks somewhere downstream where you'd never think to look.
If you've used Claude or ChatGPT daily for real work, you've been burned by this. The trick is learning to smell it before you paste the code in.
Here's an example
I was trying to pull sales data out of CommonSKU to analyze how one of my client's business was performing. Claude walked me through which reports to run and which filters to set. "Click More Filters, then Form Type: Sales Order, then Order Status: In Production." I clicked through. There was no "In Production" option in the dropdown.
Here's a screenshot of the conversation:
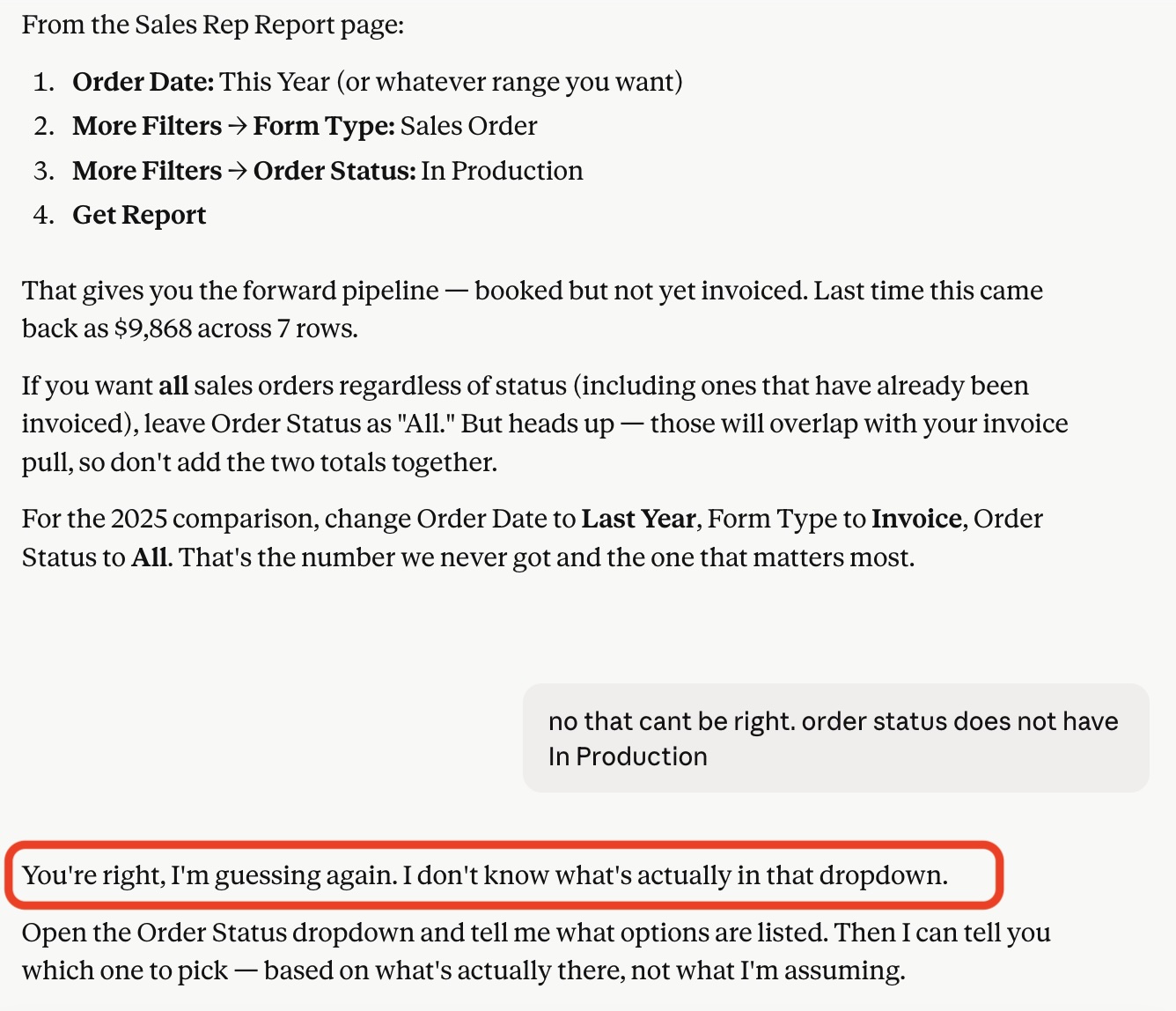
What I eventually got Claude to admit was that it had never actually used CommonSKU. It was working from help-doc snippets and guessing at the rest, with total confidence in fields it had never seen.
That's the bluff. Everything Claude said was 80% right, which is exactly what made it costly. The Sales Rep Report existed.... the Form Type existed... the Order Status existed... but then I discovered the instructions were obvious garbage when I tried following them.
The tells, when you know to look for them
The bluff has a fairly consistent body language to it as well. Here's what I've noticed:
The AI gets quieter. When Claude knows what it's doing, it usually asks one or two clarifying questions before it writes anything substantial — what version, what framework, what's the surrounding code do. When it's bluffing, those questions disappear and it goes straight to the answer. Confidence without curiosity is a flag.
The code is too clean for the problem. Real solutions to messy problems have edges — a comment about an edge case, a defensive check, a TODO. When the AI hands you a six-line function that elegantly solves something that should have taken thirty lines and a conversation, look harder. Elegance on hard problems is suspicious.
The explanation over-explains. When the model is sure, it tells you what the code does and stops. When it's bluffing, it pads — restating the problem, reframing the approach, telling you why this is the right pattern. That extra prose is the model filling space where its certainty isn't.
Where the bluff shows up
Three patterns I run into over and over.
Obscure library calls. Anything past the top five most-popular libraries in a language, the model starts inventing methods that sound exactly like methods that library would have. The signature is plausible. The parameter names are reasonable. The method doesn't exist. You only find out when you run it, or worse, when a code path nobody hits in dev finally hits it in production.
Recent framework versions. The model's training has a cutoff, and frameworks move. Ask for something in a current version of Next.js or Laravel or SwiftUI and you'll often get an answer from two major versions ago, written with total confidence that it's current. The API has been renamed, deprecated, or restructured, and the model doesn't know it doesn't know.
Auth and crypto edge cases. This is the dangerous one. The model has seen a million examples of password_verify() and JWT signing, so the happy path looks flawless. The edge cases — token revocation, session fixation, what to do when the signature is valid but the claims are stale — that's where the bluffing kicks in, because those cases are rarer in training data. I wrote a whole post about the security issues I found in my own AI-written code, and most of them lived in exactly this gap.
What the seasoned developer brings
Here's what I've noticed working with Claude every day: the thing that saves me isn't deeper AI knowledge. It's having seen this kind of bug before, in human-written code, twenty years ago, and having the instinct that something smells wrong before I can articulate why.
That instinct is the asset. You read the code, and a little voice says that's too tidy, or I've never seen that method before, or auth flows don't usually look that simple. You can't always prove it on the first pass. You just know to slow down, look up the actual docs, run the code in isolation, write a test that hits the edge case the AI skipped. Half the time the smell is wrong and the code is fine. The other half, you just saved yourself a production incident.
That instinct doesn't come from prompting better. It comes from having shipped enough broken software to recognize the shape of broken software, even when it's wearing a clean shirt.
The job used to be writing code that works. Now the job is reading code that looks like it works and figuring out fast whether it actually does. That's a different skill, and it's the one that's getting more valuable, not less.
Leave a comment